AlphaZero와 Stockfish 사이의 게임 1에서 오늘 호기심을 충족시키는 데 도움이되는 예제 1을 사용하여 두 번째 요점을 자세히 설명하는 것이 가장 좋습니다.
1 분 / 이동 시간 제한
Stockfish의 성능은 시간 제한 과 하드웨어 구성에 따라 달라 지므로 누군가 누군가 CPU 스레드를 두 배로 늘린 경우를 생각하면 첫 번째 구성에서보다 솔루션을 찾는 데 시간이 덜 필요합니다 (반드시 절반이 아님).
Chess.com에 게시 된 첫 번째 보고서에서 누군가는 컴퓨터에서 동일한 스톡 피쉬를 사용하여 동일한 결과를 재현 할 수 없기 때문에 Stockfish 가 최적으로 재생되지 않았다고 주장했습니다. 그는 아래 위치에서 (게임 1-11 이동) Stockfish는 전혀 의미가없는 Kg1-h1 (왕을 움직였다)을했다고 말했다. 다른 한편으로, 그의 컴퓨터에있는 비축 어는 Be3 (어두운 비숍 감독 이동)과 같이보다 발전된 움직임을 보였으며, 그 위치를 보자.
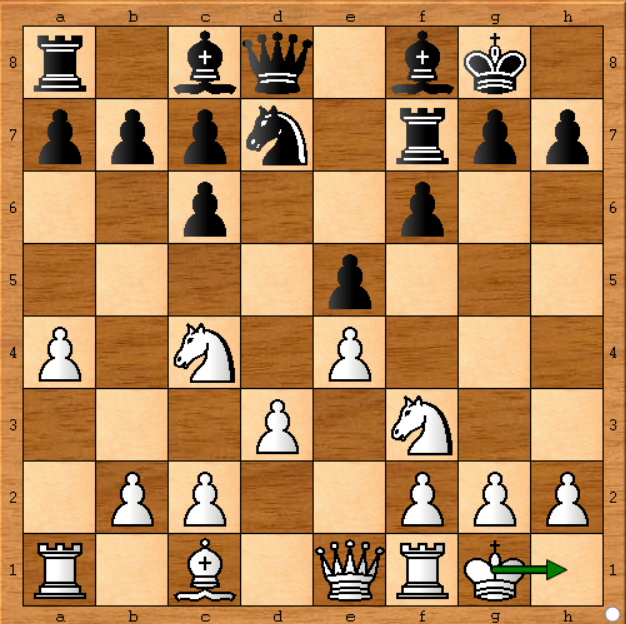
그렇습니다. 수동적 인 움직임이었고 Stockfish는 더 발전한 움직임을 보였을 것 같습니다. 그러나 그는 틀렸다. 왜? 그는 15 초 동안 스톡 피쉬를 달렸고 1 시간 동안 뛰었다면 Kg1-h1을 그 위치에서 가장 잘 움직였을 것입니다. Stockfish는 가능한 모든 이동을보다 깊이 분석 할 때 결정을 변경합니다. 다음은 원래 회신에서 말한 내용입니다 .
나는 그 자리에서 최신 비늘을 움직였다 (11 번 이동) :
- 처음에는 엔진이 약 1 분 동안 작동 할 때 b4를 최적의 이동으로 제공합니다. 그 후 Be3이 더 좋다고 결정합니다.
그러나 1,400k 노드에서 실행되는 하드웨어에서 5 분이 지나면 최적의 이동으로 Kh1을 사용하기로 결정합니다.
이 논문에서, 스톡 피쉬는 초당 70,000k 개의 위치를 계산하고 이동 당 1 분 동안 실행되는데, 이는 내 하드웨어의 약 50 배이므로 50 분 동안 계속 실행하도록하겠습니다 ... Kg1-h1은 여전히 Stockfish를위한 선택.
시간 제한이 핵심
위의 경우, 결정이 동일했기 때문에 Stockfish가 두 번 실행 된 경우 중요하지 않을 것입니다.하지만 다음 단계에서는 분명히 다음과 같습니다.
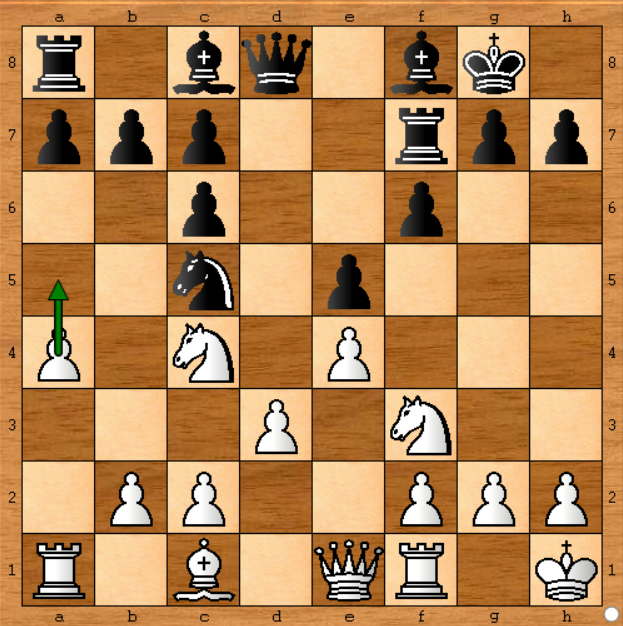
이 위치에서 Stockfish는 폰을 왼쪽 ( a4-a5 ) 으로 옮기기로 결정했습니다 . 실제 게임에서 Stockfish 보다 초당 1,400k 노드 속도로 Stockfish 엔진을 실행하는 컴퓨터가 있다고 가정 해 봅시다 ( 논문 에서 70,000kn / s라고 함). 매번 50 분 동안 게임을 실행하면 게임을 시뮬레이션 할 수 있습니다. 괜찮아.
위의 위치에서 Stockfish 분석을 실행 한 결과는 다음과 같습니다.
- Stockfish는 몇 가지 움직임을 제안하기 시작했지만 내 컴퓨터에서 6 분 ( 실제 게임의 Stockfish에서 7.2 초 에 해당) 후 게임이 진행되는 것처럼 a4-a5를 선호했습니다 .
그것은 좋지만 1 분 동안 게임에서 Stockfish의 계산에 도달하기 위해 50 분 동안 계속 실행했습니다.
슬픈 사실은 Stockfish가 시간 제한으로 인해 모든 게임을 잃었다 고 생각한다는 것입니다. Stockfish는 시간이 지남에 따라보다 심층적 인 검색 및 평가를 받고 게임에서 얕은 깊이에서 많은 움직임을 고려할 수있는 오프닝 북을 사용할 수 없었습니다. 실제 게임에서 a4-a5 가 재생되어 (초당 7 천만 개의 위치를 평가할 수 있다고 가정 할 때) 게임에서 Stockfish가 이동에 21.6 초 이상을 소비하지 않았 음을 보여줍니다. 그렇지 않으면 실제 게임에서 다른 3 가지 동작으로 결정을 변경했을 것입니다. Stockfish가 더 적은 메모리를 소비했기 때문에이 이유는 여전히 명확하지 않습니다 ( 원본 논문에서 언급 한 1GB에 비해 약 ~ 130MB의 RAM이 모든 것이 해시 테이블에 있다고 가정).
결론
내가 지적했듯이 Stockfish를 실행 한 하드웨어는 내가 분석 한 움직임에 따라 내 것보다 18 배 빠릅니다 (업데이트 : 단일 코어). AlphaZero가 4 시간 안에 네트워크를 훈련시키기 위해 그러한 하드웨어를 실제로 사용할 수 있는지는 확실하지 않습니다. 체스와 같은 게임에서는 너무 낮다고 가정 할 수 있습니다. 또한 AlphaZero는 학습에 많은 시간을 보냈으며 여기에는 견고한 개구부 (그리고 논문에서 지적한 바와 같이 특정 개구부에 대한 선호도)가 포함됩니다. 반면, Stockfish는 개구부에 장애가 있었으며 각 움직임에서 60 초 동안 초당 7 천만 개의 위치를 평가하지 않았습니다.
마지막으로, 내가 말한 모든 것은 내 가정에 근거한 것입니다. 물론 AlphaZero와 게임의 결과는 매우 흥미로 웠습니다. 그러나 나는 Stockfish 놀이가 내 컴퓨터에서 얻는 것과 같은 게임을보고 싶었습니다. 즉, 더 많은 시간과 책이 허용됩니다. 또한 모든 이동에서 Stockfish 분석 결과를 쉽게 얻을 수 있으며, 성능이 얼마나 우수한지 보여주기 위해이를 릴리스하기를 바랍니다.