저는 Gimli의 저자 중 한 사람입니다. 우리는 이미 C에 2 개의 트윗 (280 문자) 버전을 가지고 있지만 얼마나 작은 지 알고 싶습니다.
Gimli ( paper , website )는 CES ( Cryptographic Hardware and Embedded Systems) 2017 (9 월 25-28 일) 에서 발표 될 보안 수준이 높은 암호화 순열 설계가 적용된 고속입니다 .
작업
평소와 같이 : 선택한 언어로 작게 사용할 수있는 Gimli 구현.
입력 384 비트 (또는 48 바이트 또는 부호없는 int ... 12 )로 가져 와서이 384 비트에 적용된 Gimli의 결과를 리턴 (포인터를 사용하는 경우 제자리에서 수정 될 수 있음) 할 수 있어야합니다 .
10 진수, 16 진수, 8 진수 또는 2 진수로의 입력 변환이 허용됩니다.
잠재적 코너 케이스
정수 인코딩은 리틀 엔디안 인 것으로 가정합니다 (예 : 이미 가지고있는 것).
로 이름 Gimli을 바꿀 수 G있지만 여전히 함수 호출이어야합니다.
누가 이겼어?
이것은 코드 골프이므로 바이트 단위의 최단 답변이 이깁니다! 물론 표준 규칙이 적용됩니다.
참조 구현은 다음과 같습니다.
노트
몇 가지 우려가 제기되었습니다.
"헤이 갱, 다른 언어로 무료로 내 프로그램을 구현하십시오."
내 대답은 다음과 같습니다.
Java, C #, JS, Ocaml에서 쉽게 할 수 있습니다 ... 재미 있습니다. 현재 우리 (Gimli 팀)는 AVR, Cortex-M0, Cortex-M3 / M4, Neon, SSE, SSE-unrolled, AVX, AVX2, VHDL 및 Python3에서 구현하고 최적화했습니다. :)
김리 소개
상태
Gimli는 일련의 라운드를 384 비트 상태로 적용합니다. 이 상태는 3 × 4 × 32 차원의 평행 육면체 또는 32 비트 워드의 3 × 4 행렬로 표시됩니다.
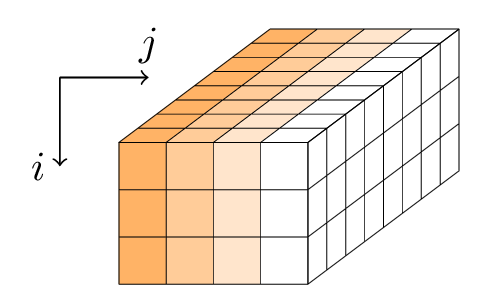
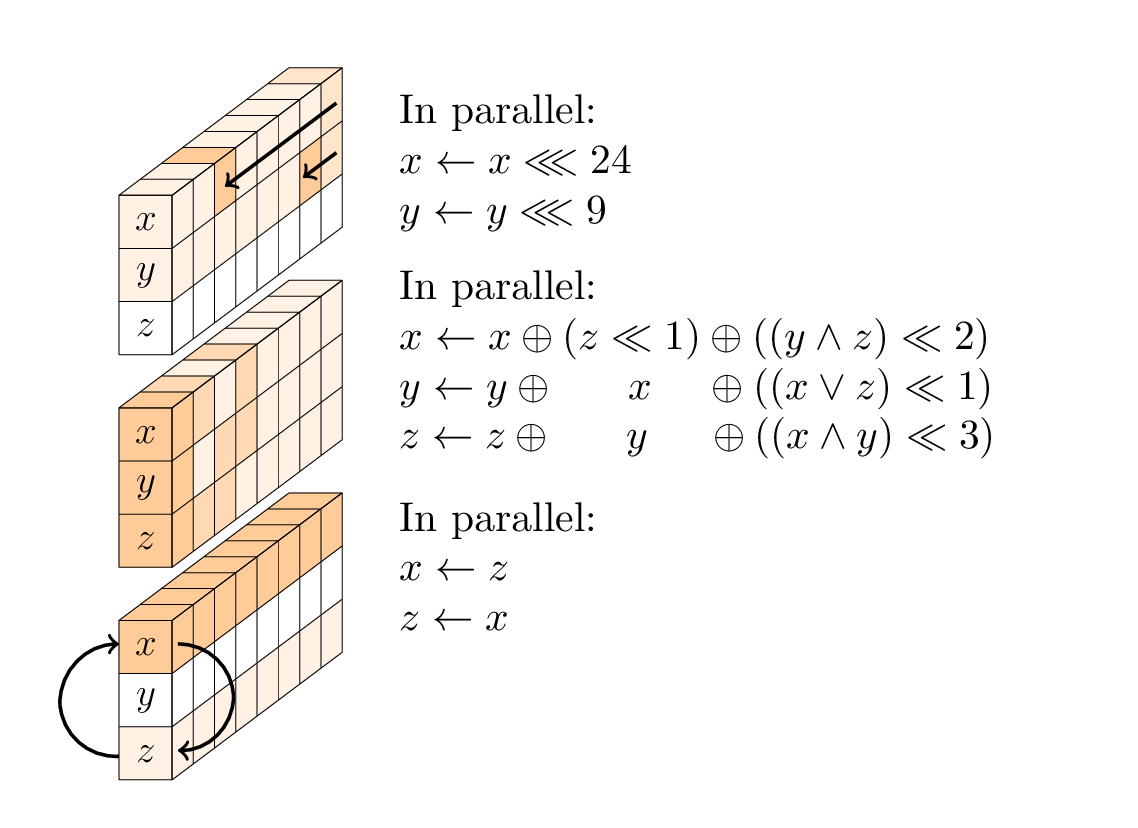
각 라운드는 세 가지 작업의 순서입니다.
- 비선형 층, 구체적으로 각 열에 적용되는 96 비트 SP- 박스;
- 매 두번째 라운드에서, 선형 혼합 층;
- 4 번째 라운드마다 지속적으로 추가됩니다.
비선형 레이어
SP-box는 세 가지 하위 작업으로 구성됩니다. 첫 번째 단어와 두 번째 단어의 회전; 3- 입력 비선형 T- 기능; 그리고 첫 번째 단어와 세 번째 단어의 교체.
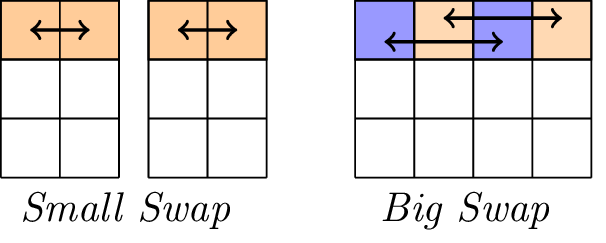
선형 레이어.
선형 계층은 스왑 작업 (Small-Swap 및 Big-Swap)으로 구성됩니다. 스몰 스왑은 1 라운드부터 4 라운드마다 발생합니다. 빅 스왑은 3 라운드부터 4 라운드마다 발생합니다.
둥근 상수.
김리에는 24,23, ..., 1의 24 라운드가 있습니다. 라운드 수 r이 24,20,16,12,8,4 일 때 우리는 라운드 상수 (0x9e377900 XOR r)를 첫 번째 상태 단어로 XOR합니다.
C의 참조 소스
#include <stdint.h>
uint32_t rotate(uint32_t x, int bits)
{
if (bits == 0) return x;
return (x << bits) | (x >> (32 - bits));
}
extern void gimli(uint32_t *state)
{
int round;
int column;
uint32_t x;
uint32_t y;
uint32_t z;
for (round = 24; round > 0; --round)
{
for (column = 0; column < 4; ++column)
{
x = rotate(state[ column], 24);
y = rotate(state[4 + column], 9);
z = state[8 + column];
state[8 + column] = x ^ (z << 1) ^ ((y&z) << 2);
state[4 + column] = y ^ x ^ ((x|z) << 1);
state[column] = z ^ y ^ ((x&y) << 3);
}
if ((round & 3) == 0) { // small swap: pattern s...s...s... etc.
x = state[0];
state[0] = state[1];
state[1] = x;
x = state[2];
state[2] = state[3];
state[3] = x;
}
if ((round & 3) == 2) { // big swap: pattern ..S...S...S. etc.
x = state[0];
state[0] = state[2];
state[2] = x;
x = state[1];
state[1] = state[3];
state[3] = x;
}
if ((round & 3) == 0) { // add constant: pattern c...c...c... etc.
state[0] ^= (0x9e377900 | round);
}
}
}C의 트윗 가능한 버전
이것은 사용 가능한 가장 작은 구현은 아니지만 C 표준 버전 (따라서 UB가 없으며 라이브러리에서 "사용 가능")을 원했습니다.
#include<stdint.h>
#define P(V,W)x=V,V=W,W=x
void gimli(uint32_t*S){for(long r=24,c,x,y,z;r;--r%2?P(*S,S[1+y/2]),P(S[3],S[2-y/2]):0,*S^=y?0:0x9e377901+r)for(c=4;c--;y=r%4)x=S[c]<<24|S[c]>>8,y=S[c+4]<<9|S[c+4]>>23,z=S[c+8],S[c]=z^y^8*(x&y),S[c+4]=y^x^2*(x|z),S[c+8]=x^2*z^4*(y&z);}테스트 벡터
에 의해 생성 된 다음 입력
for (i = 0;i < 12;++i) x[i] = i * i * i + i * 0x9e3779b9;그리고 "인쇄 된"값
for (i = 0;i < 12;++i) {
printf("%08x ",x[i])
if (i % 4 == 3) printf("\n");
}그러므로:
00000000 9e3779ba 3c6ef37a daa66d46
78dde724 1715611a b54cdb2e 53845566
f1bbcfc8 8ff34a5a 2e2ac522 cc624026
반환해야합니다 :
ba11c85a 91bad119 380ce880 d24c2c68
3eceffea 277a921c 4f73a0bd da5a9cd8
84b673f0 34e52ff7 9e2bef49 f41bb8d6