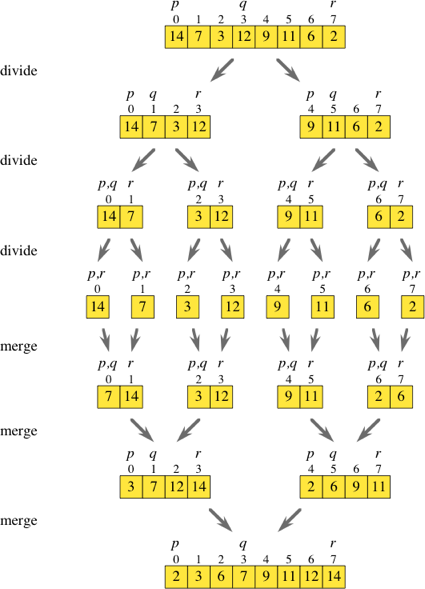
따라서 병합 정렬은 나누기 및 정복 알고리즘입니다. 위의 다이어그램을 보면서 기본적으로 모든 나누기 단계를 무시할 수 있는지 생각했습니다.
2만큼 점프하면서 원래 배열을 반복하면 인덱스 i 및 i + 1에서 요소를 가져 와서 자체 정렬 배열에 넣을 수 있습니다. 이러한 하위 배열을 모두 갖추면 (그림에 표시된대로 [7,14], [3,12], [9,11] 및 [2,6]) 일반 병합 루틴을 계속 진행할 수 있습니다. 정렬 된 배열
배열을 반복하고 필요한 하위 배열을 즉시 생성하는 것이 분할 단계를 전체적으로 수행하는 것보다 덜 효율적입니까?
관련 : cs.stackexchange.com/questions/77075/…
—
Omar