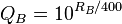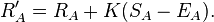문제에 대한 대부분의 순진한 접근 방식에는 몇 가지 심각한 문제가 있습니다. 최악의 경우는 bash.org 및 qdb.us 가 따옴표를 표시 하는 방법입니다. 사용자는 따옴표를 위로 (+1) 또는 아래로 (-1) 투표 할 수 있으며 최고 따옴표 목록은 총 순 점수를 기준으로 정렬됩니다. 이것은 끔찍한 시간 편견으로 고통받습니다. 오래된 인용문은 약간 유머러스하더라도 단순한 수명을 통해 엄청난 수의 긍정적 인 투표를 축적했습니다. 이 알고리즘은 농담이 나이가 들어감에 따라 더 재미있어졌지만-저를 믿으십시오-그렇지 않다면 의미가있을 수 있습니다.
이 문제를 해결하기위한 다양한 시도가 있습니다. 기간 당 긍정적 인 투표 수를보고, 최근 투표에 가중치를 부여하고, 오래된 투표에 대한 감쇄 시스템을 구현하고, 긍정적 인 투표와 부정적 투표의 비율을 계산하는 등 대부분의 다른 결함이 있습니다.
가장 좋은 해결책은 웹 사이트 The Funniest The Cutest , The Fairest , Best Thing에서 사용하는 수정 된 Condorcet 투표 시스템입니다 .
시스템은 직면 한 것들 중 보통이기는 비율을 기준으로 각각에 숫자를 부여합니다. 따라서 각각은 백분율 점수 NumberOfThingsIBeat / (NumberOfThingsIBeat + NumberOfThingsThatBeatMe)를 얻습니다. 또한 세트의 합리적인 비율과 비교 될 때까지 항목이 최상위 목록에서 제외됩니다.
세트에 Condorcet 우승자가있는 경우이 방법으로 찾을 수 있습니다. 통계적 성격을 감안할 때 그럴 가능성은 낮기 때문에 Condorcet 승자가되는 데 "가장 가까운"사람을 찾습니다.
이러한 시스템 구현에 대한 자세한 내용은 랭킹 페어 의 Wikipedia 페이지 가 도움이 될 것입니다.
알고리즘은 사람들이 두 개체를 비교하도록 요구하지만 (Pick-A-or-B 옵션) 솔직히 그것은 좋은 것입니다. 인간이 추상적 인 순위에있는 것보다 두 대상을 비교하는 데 훨씬 더 뛰어나다는 것이 의사 결정 이론에서 매우 잘 받아 들여지고 있다고 생각합니다. 수백만 년의 진화를 통해 우리는 나무에서 가장 좋은 사과를 고르는 데 능숙하지만, 우리가 고른 사과가 사과의 진정한 플라톤 형태에 얼마나 가깝게 갈지 결정하는 것은 끔찍합니다. (이것이 분석 계층 구조 프로세스 가 그토록 멋진 이유입니다 ...하지만 주제에서 약간 벗어난 것입니다.)
마지막으로해야 할 점은 SO가 bash.org 의 알고리즘 과 매우 유사한 최상의 답변 을 찾기 위해 알고리즘을 사용하여 최상의 견적을 찾는 것입니다. 여기에서는 잘 작동하지만 끔찍하게 실패합니다. 왜냐하면 오래되고 높은 등급을 받았지만 지금은 구식 답변이 편집 될 가능성이 높기 때문입니다. bash.org는 편집을 허용하지 않으며, 가능하더라도 지금까지 사용 된 인터넷 밈에 대한 10 년 된 농담을 편집하는 방법도 명확하지 않습니다. 문제의 세부 사항에 따라 다릅니다. :-)