나는 몇 달 동안이 질문을했다. softmax를 출력 함수로 영리하게 추측 한 다음 입력을 softmax에 대한 로그 확률로 해석합니다. 당신이 말했듯이, 왜 모든 출력을 그 합으로 나눠서 정규화하지 않겠습니까? 6.2.2 절의 Goodfellow, Bengio 및 Courville (2016) 의 딥 러닝 책 에서 답을 찾았습니다 .
마지막 숨겨진 레이어가 z를 활성화로 제공한다고 가정 해 봅시다. 그러면 softmax는 다음과 같이 정의됩니다

아주 짧은 설명
softmax 함수의 exp는 대 엔트로피 손실의 로그를 대략 상쇄하여 z_i에서 손실이 대략 선형이되도록합니다. 이로 인해 모델이 잘못되었을 때 대략 일정한 기울기가 발생하여 빠르게 보정 할 수 있습니다. 따라서 잘못된 포화 소프트 맥스가 사라지는 구배를 유발하지 않습니다.
간단한 설명
신경망을 훈련시키는 가장 보편적 인 방법은 Maximum Likelihood Estimation입니다. 우리는 훈련 데이터의 가능성을 극대화하는 방식으로 매개 변수 세타를 추정합니다 (크기 m). 전체 트레이닝 데이터 세트의 가능성은 각 샘플의 우도의 곱이므로, 최대화하기 쉽다 로그 우도 데이터 집합 및 이에 K로 인덱싱 된 각 샘플의 로그 우도의 합 :
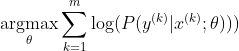
이제 z가 주어진 소프트 맥스에만 초점을 맞 춥니 다.
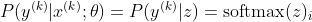
나는 k 번째 샘플의 올바른 클래스입니다. 이제 softmax의 로그를 가져 와서 샘플의 로그 우도를 계산하면 다음과 같은 결과가 나타납니다.
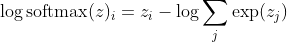
z의 큰 차이에 대해 대략적으로 대략적인
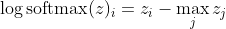
먼저 선형 구성 요소 z_i를 볼 수 있습니다. 둘째, 두 가지 경우에 대해 max (z)의 동작을 검사 할 수 있습니다.
- 모형이 정확하면 max (z)는 z_i가됩니다. 따라서 로그 우도는 z_i와 z의 다른 항목 사이의 차이가 커짐에 따라 0으로 나타납니다 (즉 1의 우도).
- 모형이 올바르지 않으면 max (z)는 다른 z_j> z_i입니다. 따라서 z_i를 추가해도 -z_j가 완전히 취소되지 않으며 로그 우도는 대략 (z_i-z_j)입니다. 이것은 로그 가능성을 높이기 위해 z_i를 높이고 z_j를 줄이려면 어떻게해야하는지 모델에 명확하게 알려줍니다.
모델이 잘못된 샘플에 의해 전체 로그 우도가 지배적임을 알 수 있습니다. 또한 모델이 실제로 부정확하더라도 포화 된 softmax가 발생하더라도 손실 함수는 포화되지 않습니다. z_j에서 거의 선형으로, 거의 일정한 기울기를 가짐을 의미합니다. 이를 통해 모델이 신속하게 수정 될 수 있습니다. 예를 들어, 평균 제곱 오류의 경우에는 해당되지 않습니다.
긴 설명
softmax가 여전히 임의의 선택 인 것 같으면 로지스틱 회귀 분석에서 S 자형을 사용하는 데 대한 정당성을 살펴볼 수 있습니다.
왜 다른 것 대신 S 자형 기능이 필요한가?
softmax는 유사하게 정당화되는 다중 클래스 문제에 대한 S 자형의 일반화입니다.



