이들에는 텍스트 분류 autoencoders 종이 힌튼 및 Salakhutdinov (PCA 밀접한 관련이있다) 2 차원 LSA 제조 플롯을 보여 주었다 : 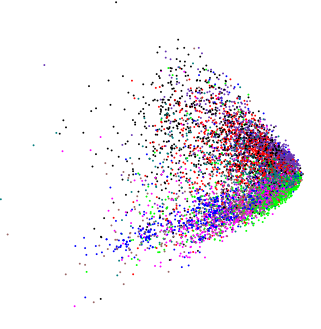 .
.
전혀 다른 약간 높은 차원의 데이터에 PCA를 적용하면 비슷한 모양의 플롯을 얻었습니다  (이 경우를 제외하고 내부 구조가 있는지 정말로 알고 싶었습니다).
(이 경우를 제외하고 내부 구조가 있는지 정말로 알고 싶었습니다).
임의의 데이터를 PCA에 공급하면 디스크 모양의 얼룩을 얻으므로이 쐐기 모양의 모양은 무작위가 아닙니다. 그 자체로 무엇을 의미합니까?
6
모든 변수가 양수 (또는 음수가 아닌) 및 연속이라고 가정합니까? 그렇다면 쐐기의 가장자리는 데이터가 0 / 음수가되는 지점입니다. 또한 양의 오른쪽으로 치우친 변수로 표시 한 것과 동일한 패턴을 얻을 수 있습니다. 관측치가 최저점에 모입니다. 양의 균일 한 랜덤 변수가있는 경우 (회전) 사각형이 나타납니다. 따라서 표시하는 것과 같은 패턴은 데이터에 대한 제약 조건 일뿐입니다. 말굽과 같은 다른 패턴이 표시 될 수 있지만 변수 범위의 제약으로 인한 것은 아닙니다.
—
개빈 심슨
@GavinSimpson 이것은 단순한 의견 이상의 것입니다. 답으로 확장하지 않겠습니까?
—
Mike Hunter
나는 아이들 (3 세와 4 세)에게이 사진들이 무엇을 생각 나게하는지 물었고 물고기라고 말했습니다. 아마도 "물고기 모양"일까요?
—
amoeba
@GavinSimpson, 감사합니다! 두 경우 모두 변수는 음수가 아니고, 두 경우 모두 정수 값입니다. 이것으로도 변화가 있습니까?
—
macleginn







