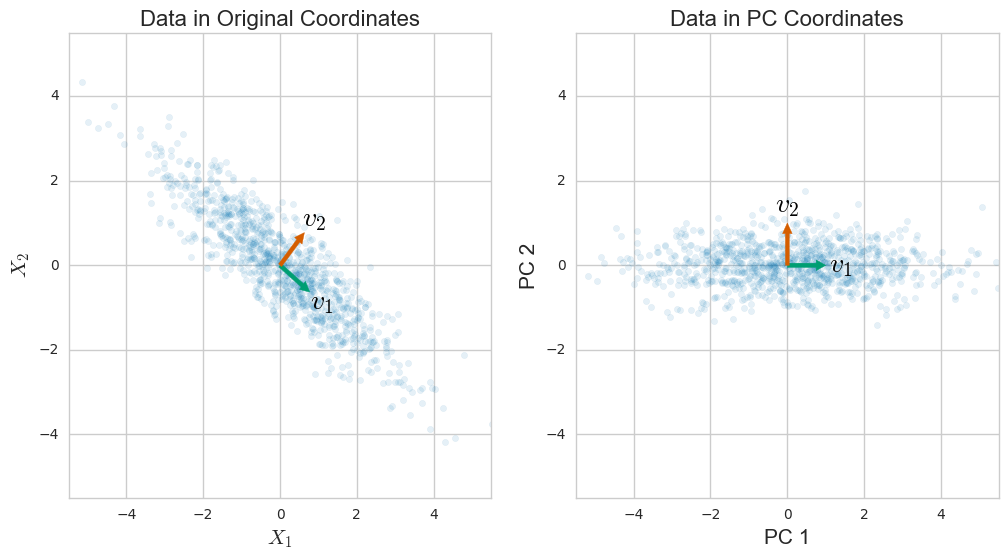
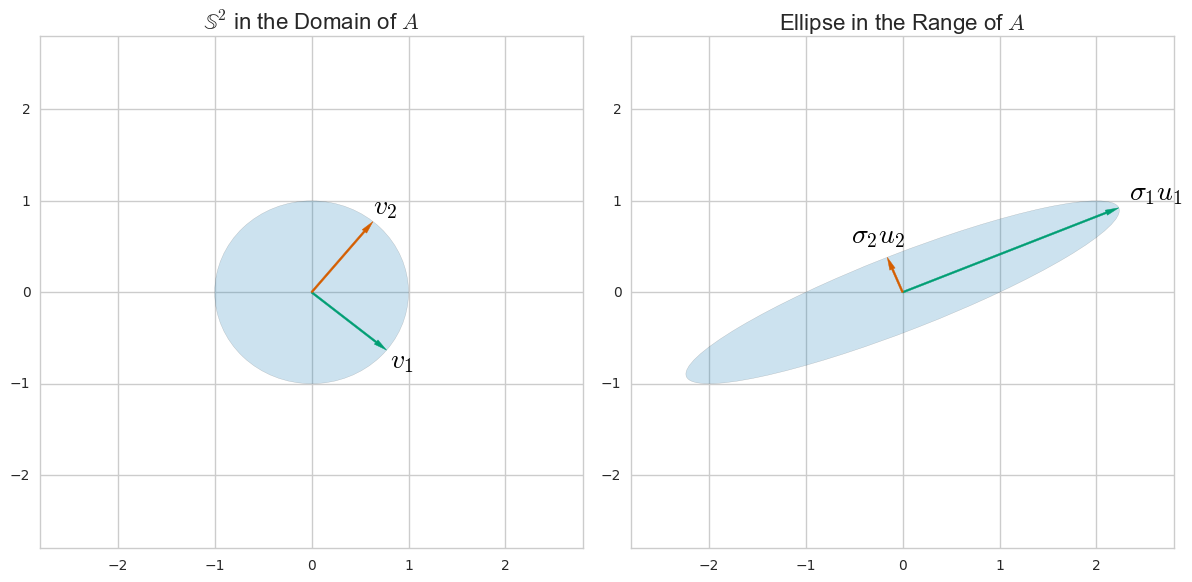
주성분 분석 (PCA)은 공분산 행렬의 고유 분해를 통해 설명됩니다. 그러나 데이터 행렬 의 단일 값 분해 (SVD)를 통해 수행 할 수도 있습니다 . 어떻게 작동합니까? 이 두 가지 방법의 관계는 무엇입니까? SVD와 PCA의 관계는 무엇입니까?
즉, 데이터 행렬의 SVD를 사용하여 차원 축소를 수행하는 방법은 무엇입니까?
8
이 FAQ 스타일 질문은 다양한 형태로 자주 요청되기 때문에 내 대답과 함께 작성되었지만 표준 스레드가 없으므로 복제본을 닫기가 어렵습니다. 이 메타 스레드 에 메타 주석을 제공하십시오 .
—
amoeba
PCA는 SVD의 특별한 경우입니다. PCA는 데이터가 이상적이고 동일한 단위로 표준화되어야합니다. 매트릭스는 PCA에서 nxn입니다.
—
Orvar Korvar
@ OrvarKorvar : 무슨 nxn 행렬에 대해 이야기하고 있습니까?
—
Cbhihe